
飞桨高层API训练营-Day2
Day2(更详细基础内容可见AIStudio中Fork的课程辅助项目)
[TOC]
神经卷积网络基础知识
- 神经元
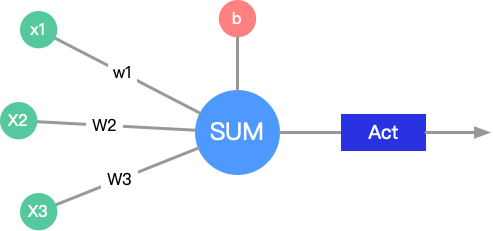
- 神经网络

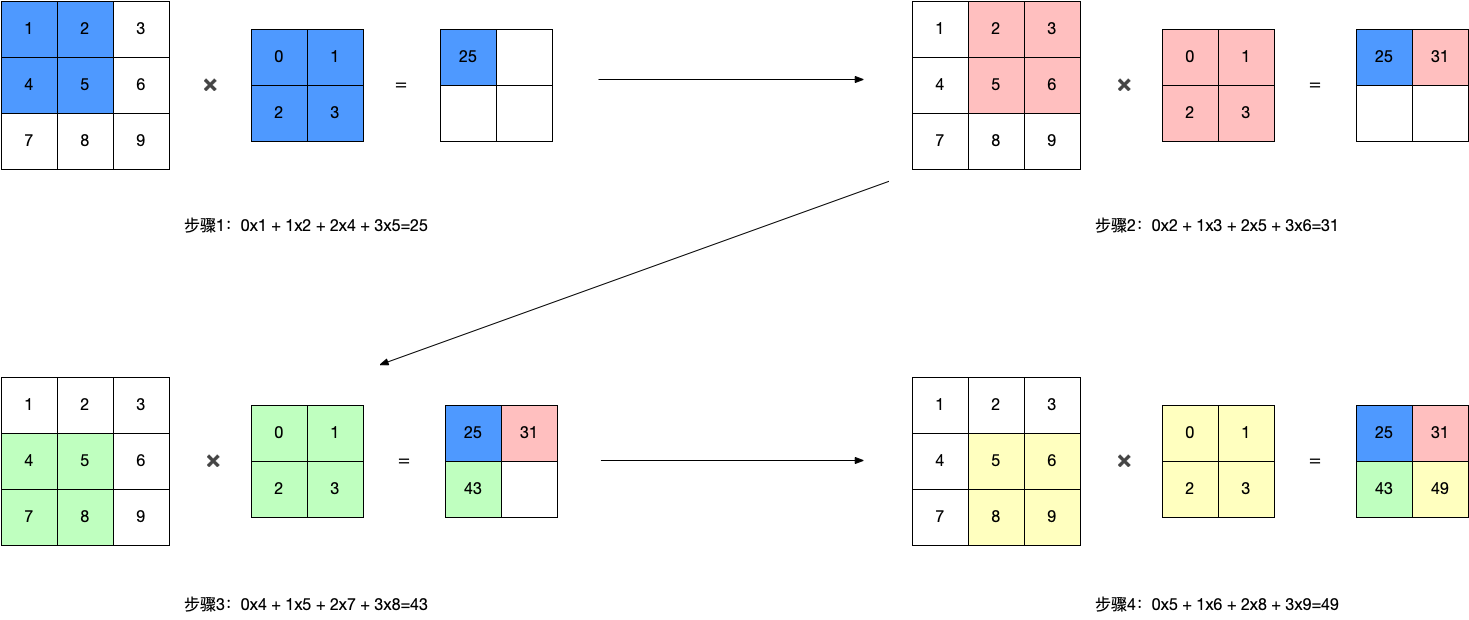
- 卷积操作
- 3.1 单通道卷积
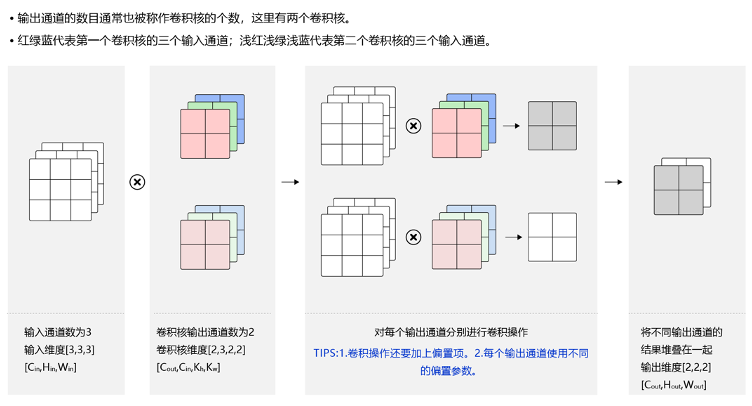
- 3.2 多通道卷积

- 3.3 多通道输出
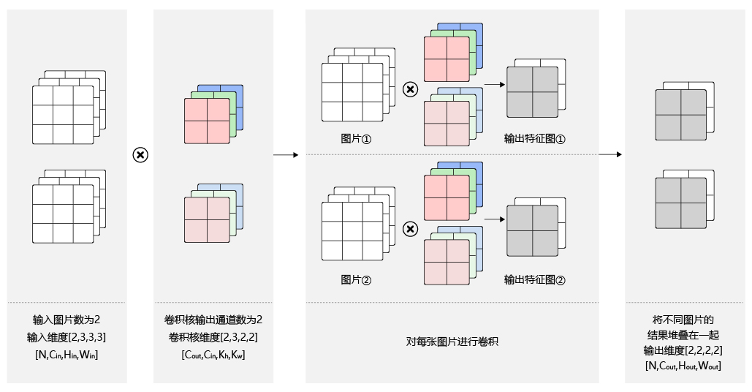
3.4 Batch
[N, C, H, W]
卷积核信息不变,卷积操作会多一定的倍数(和样本数有关)。
- 池化层
池化是使用某一位置的相邻输出的总体统计特征代替网络在该位置的输出,其好处是当输入数据做出少量平移时,经过池化函数后的大多数输出还能保持不变。比如:当识别一张图像是否是人脸时,我们需要知道人脸左边有一只眼睛,右边也有一只眼睛,而不需要知道眼睛的精确位置,这时候通过池化某一片区域的像素点来得到总体统计特征会显得很有用。由于池化之后特征图会变得更小,如果后面连接的是全连接层,能有效的减小神经元的个数,节省存储空间并提高计算效率。
池化的作用
池化层是特征选择和信息过滤的过程,过程中会损失一部分信息,但是会同时会减少参数和计算量,在模型效果和计算性能之间寻找平衡,随着运算速度的不断提高,慢慢可能会有一些设计上的变化,现在有些网络已经开始少用或者不用池化层。
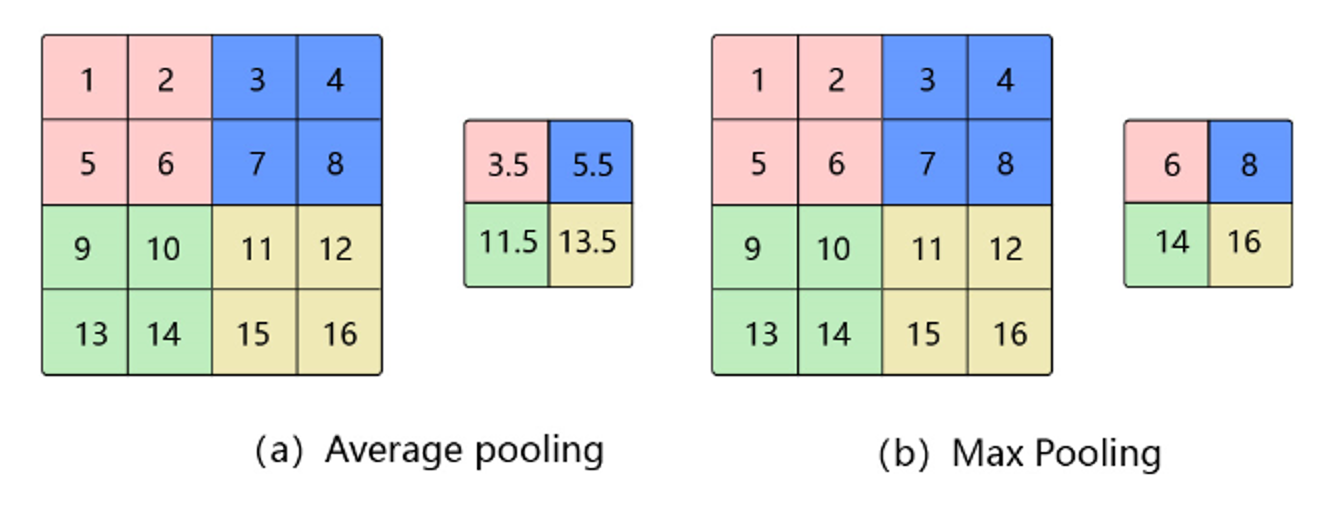
Avg Pooling 平均池化
对邻域内特征点求平均
- 优缺点:能很好的保留背景,但容易使得图片变模糊
- 正向传播:邻域内取平均
- 反向传播:特征值根据领域大小被平均,然后传给每个索引位置
Max Pooling 最大池化
对邻域内特征点取最大
- 优缺点:能很好的保留一些关键的纹理特征,现在更多的再使用Max Pooling而很少用Avg Pooling
- 正向传播:取邻域内最大,并记住最大值的索引位置,以方便反向传播
- 反向传播:将特征值填充到正向传播中,值最大的索引位置,其他位置补0
公式

- 激活函数
参考论文:https://arxiv.org/pdf/1811.03378.pdf
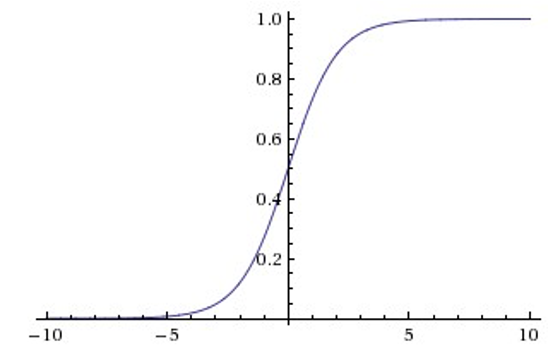
Sigmoid
Tanh
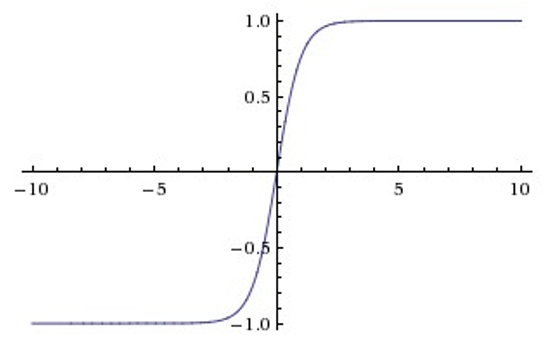
Sigmoid和Tanh激活函数有共同的缺点:即在z很大或很小时,梯度几乎为零,因此使用梯度下降优化算法更新网络很慢。
ReLU
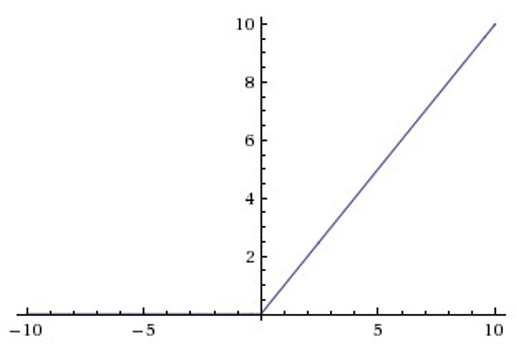
Relu目前是选用比较多的激活函数,但是也存在一些缺点,在z小于0时,斜率即导数为0。 为了解决这个问题,后来也提出来了Leaky Relu激活函数,不过目前使用的不是特别多。
- Dropout
论文:https://jmlr.org/papers/volume15/srivastava14a/srivastava14a.pdf
当一个复杂的前馈神经网络被训练在小的数据集时,容易造成过拟合。为了防止过拟合,可以通过随机丢弃部分特征节点的方式来减少这个问题发生。

基础概念
CNN:卷积神经网络
CNN基本结构:卷积层、池化层、全连接层
1*1卷积核通常是为了减少参数
数据集预处理作用:防止Loss函数过拟合,对数据进行泛华处理
单通道卷积
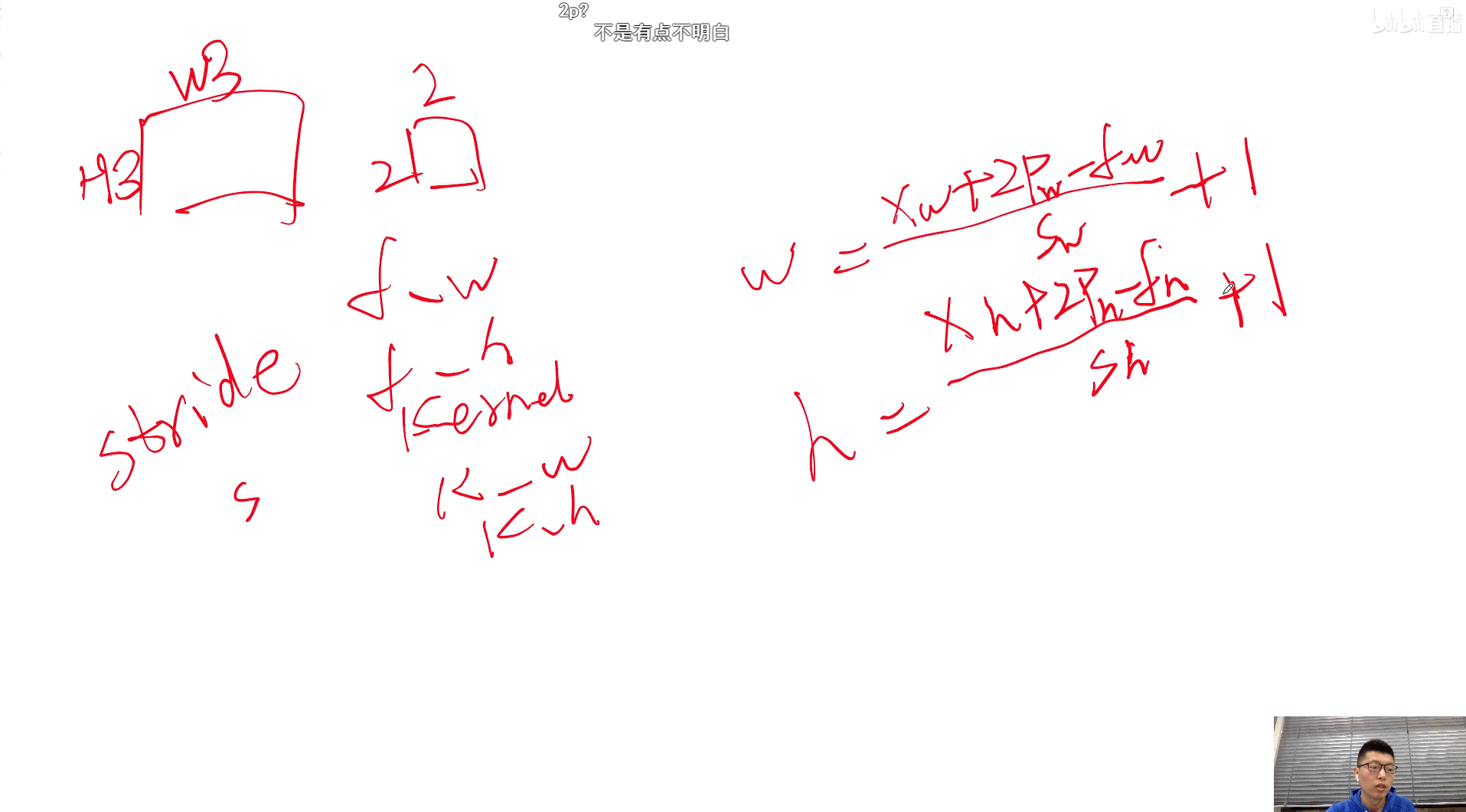
卷积神经网络发展

API

- 数据集预处理 paddle.vision.datasets.MNIST(mode = ‘train’, transform = transform)
- //定义训练数据集(mode = ‘train’) 定义测试数据集(mode = ‘test’)
- 数据归一化 paddle.vision.transforms.Normalize(mean, std)
- //mean-均值 std-方差
