
飞桨高层API训练营-Day4
Day4
[TOC]
学习内容:NPL:如何自定义数据集,实现文本分类中的情感分析任务
Day3回顾
- 回归任务输出为连续值
- 人脸关键点识别即为回归任务
- 最常用的两个损失函数MSE与交叉熵就是分别用于回归与分类任务
基础知识
情感分析
- 输入: 一个自然语言句子
- 输出: 输出这个句子的情感分类,如高兴、伤心
- 通常看作一个三分类问题
- 正向
- 中立
- 负向
文本分类通用步骤
- 文本预处理:分词、去停用词、归一等等
- 文本表示:将文本表示成向量(计算机可以理解)
- 分类模型构建:分类,svm,textcnn等等

- NLP-数据处理通用流程,以句子分类任务为例
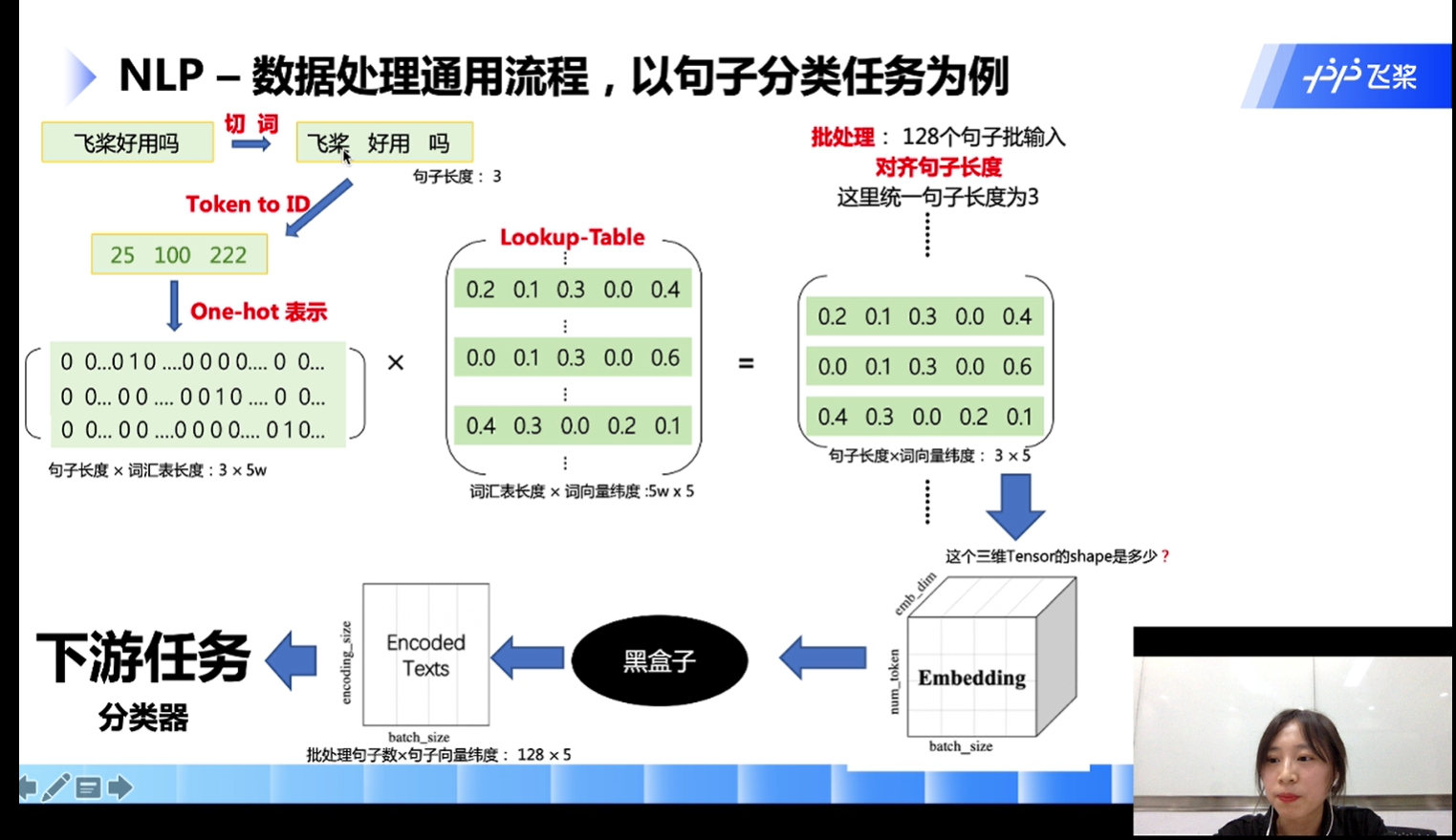
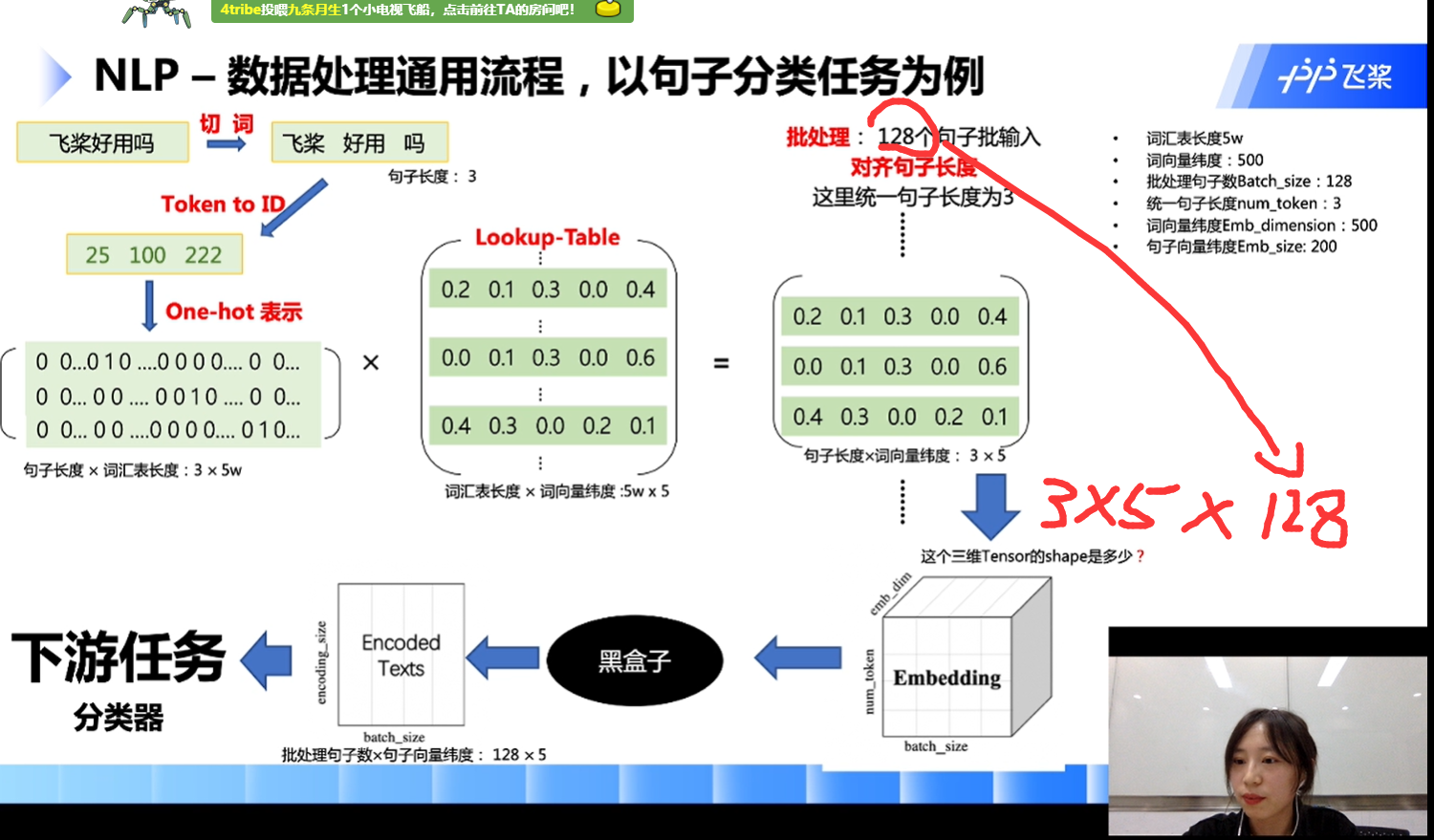
Token-涵盖字、词,一般当作词,与word-字区分
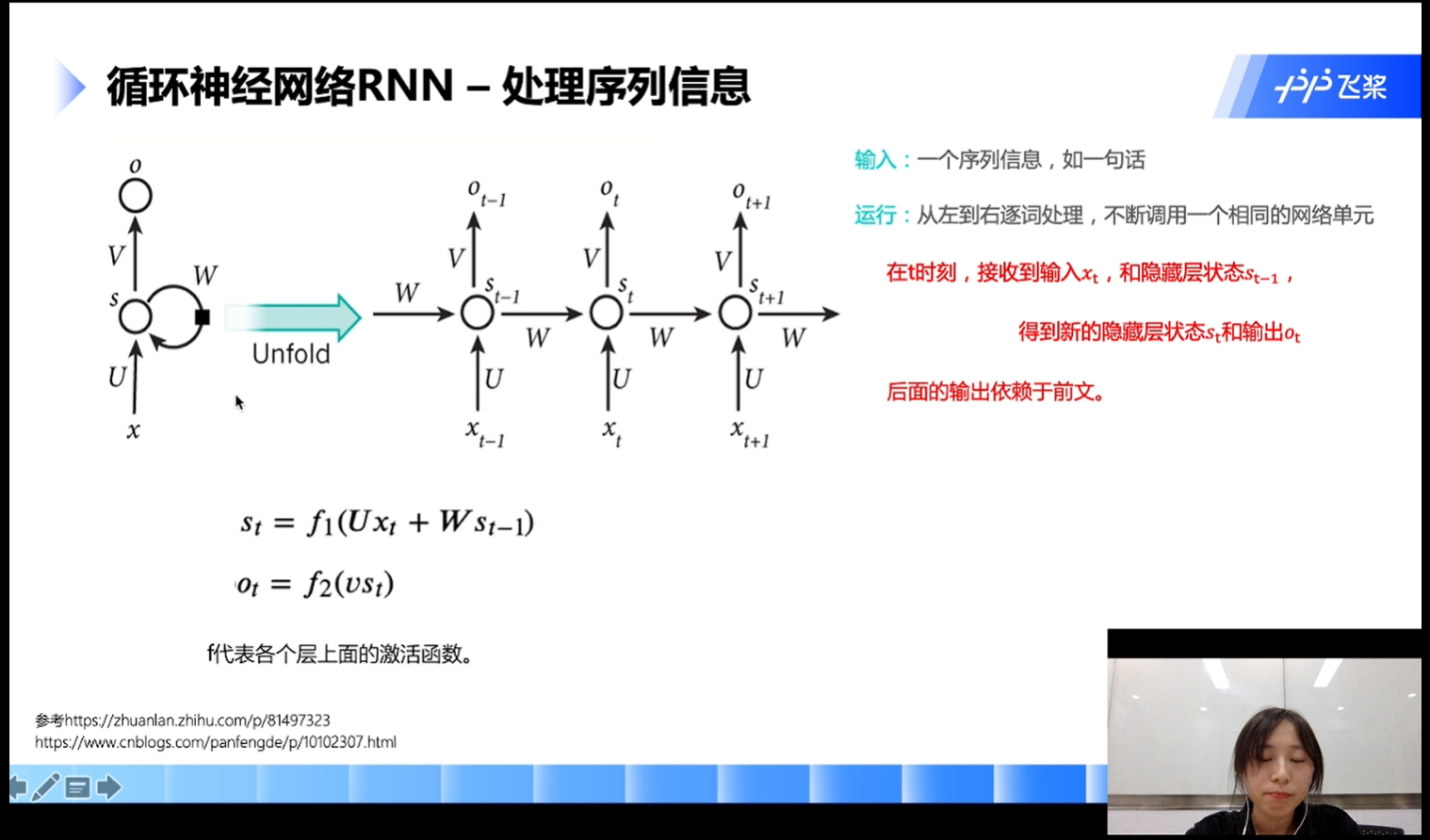
RNN——循环神经网络
- 输入:一个序列信息,如一句话
- 输出:从左到右逐词处理,不断调用一个相同的网络单元
循环神经网络——长短时记忆网络(LSTM)
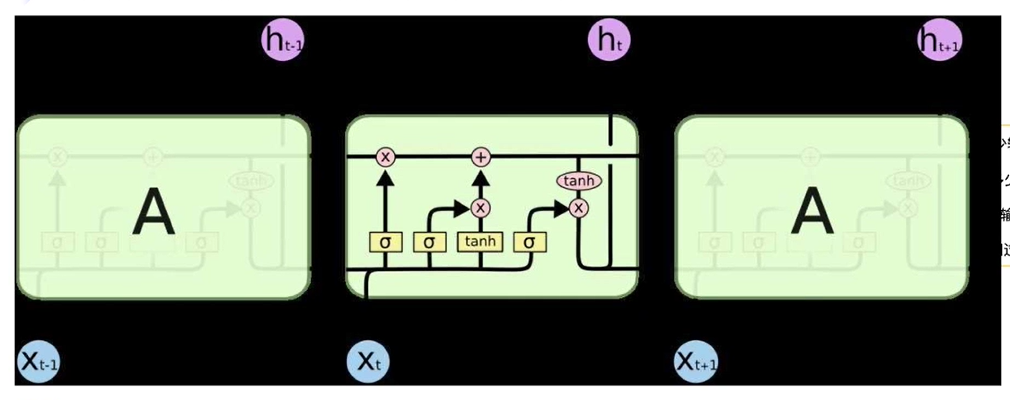
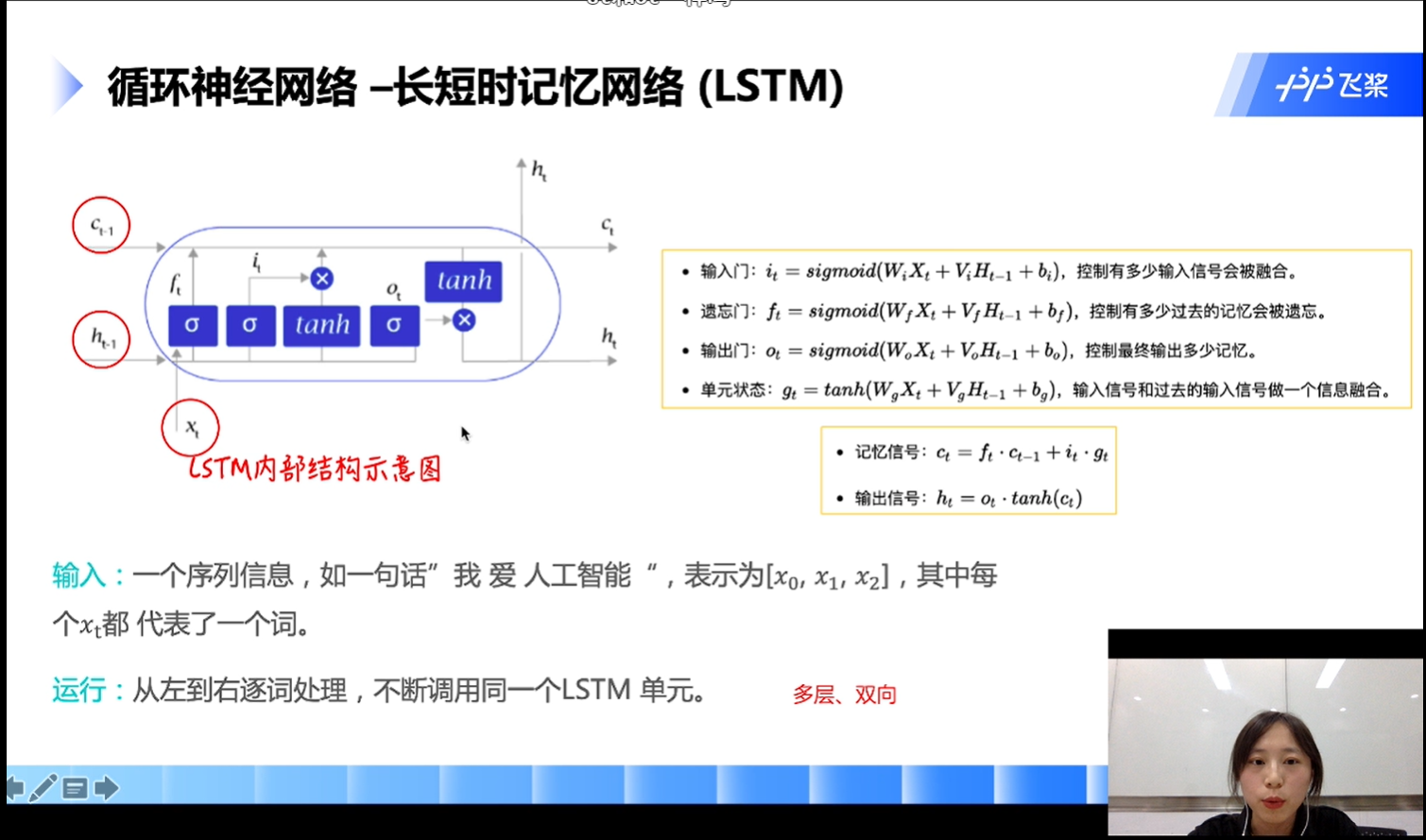
- Ct-1 : 历史记忆信息
- ht-1 : 历史隐藏信息
- xt : 当前信息
- 全连接层、线性分类分类器
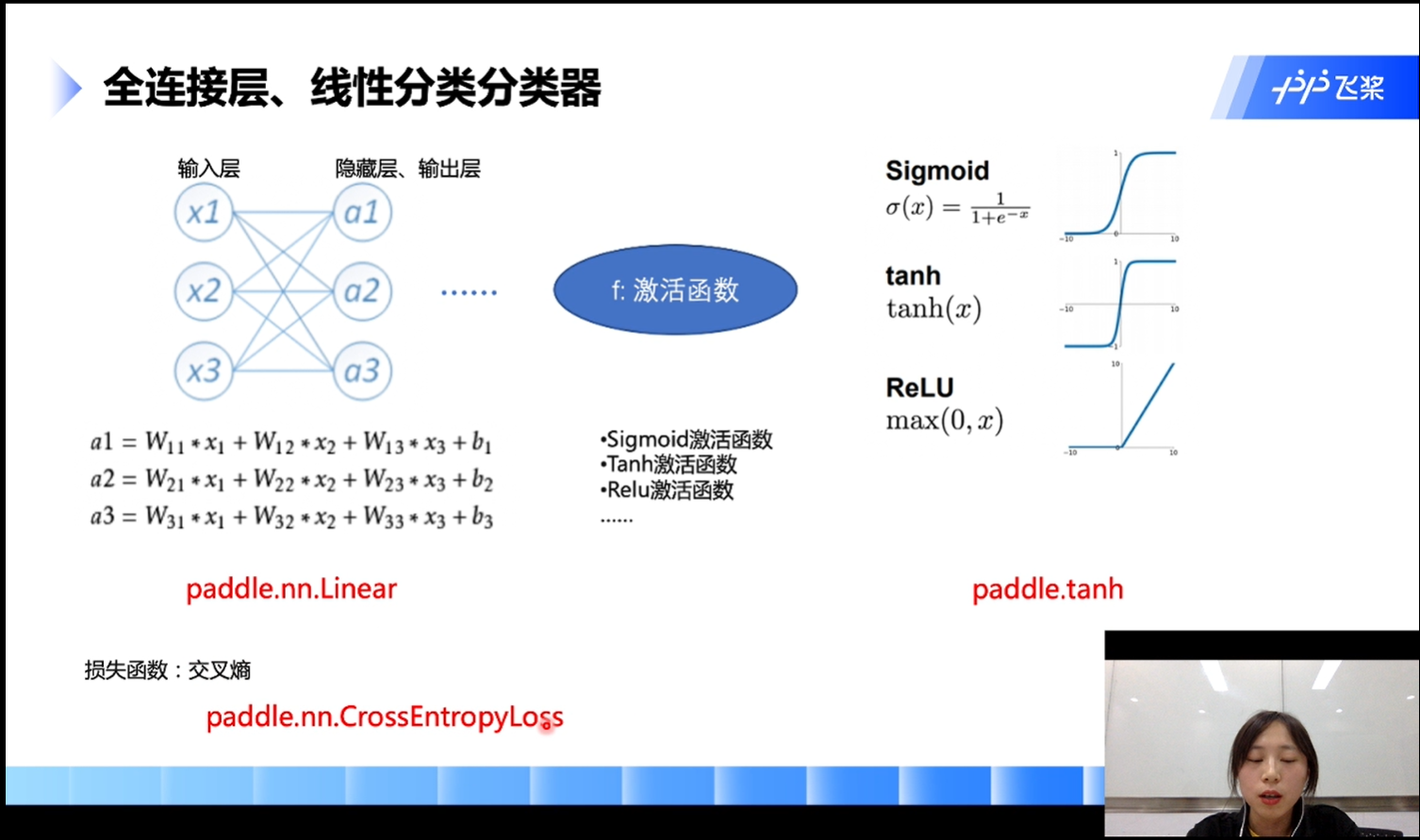
一般来说,神经网络中间层越多,表达能力越强,但要注意过多则会造成过拟合
paddlenlp—paddle的nlp子框架
数据处理
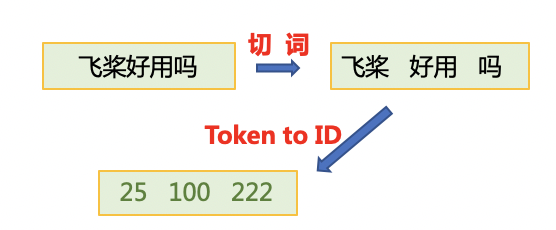
为了将原始数据处理成模型可以读入的格式,本项目将对数据作以下处理:
- 首先使用jieba切词,之后将jieba切完后的单词映射词表中单词id。
- 使用
paddle.io.DataLoader接口多线程异步加载数据。
其中用到了PaddleNLP中关于数据处理的API。PaddleNLP提供了许多关于NLP任务中构建有效的数据pipeline的常用API
| API | 简介 |
|---|---|
paddlenlp.data.Stack |
堆叠N个具有相同shape的输入数据来构建一个batch,它的输入必须具有相同的shape,输出便是这些输入的堆叠组成的batch数据。 |
paddlenlp.data.Pad |
堆叠N个输入数据来构建一个batch,每个输入数据将会被padding到N个输入数据中最大的长度 |
paddlenlp.data.Tuple |
将多个组batch的函数包装在一起 |
更多数据处理操作详见: https://github.com/PaddlePaddle/PaddleNLP/blob/develop/docs/data.md
验证集与测试集
- eg:验证集就相当于月考 测试集期末考
dropout
- 在神经网络中,随即丢弃部分神经元,它能够避免在训练数据上产生复杂的相互适应
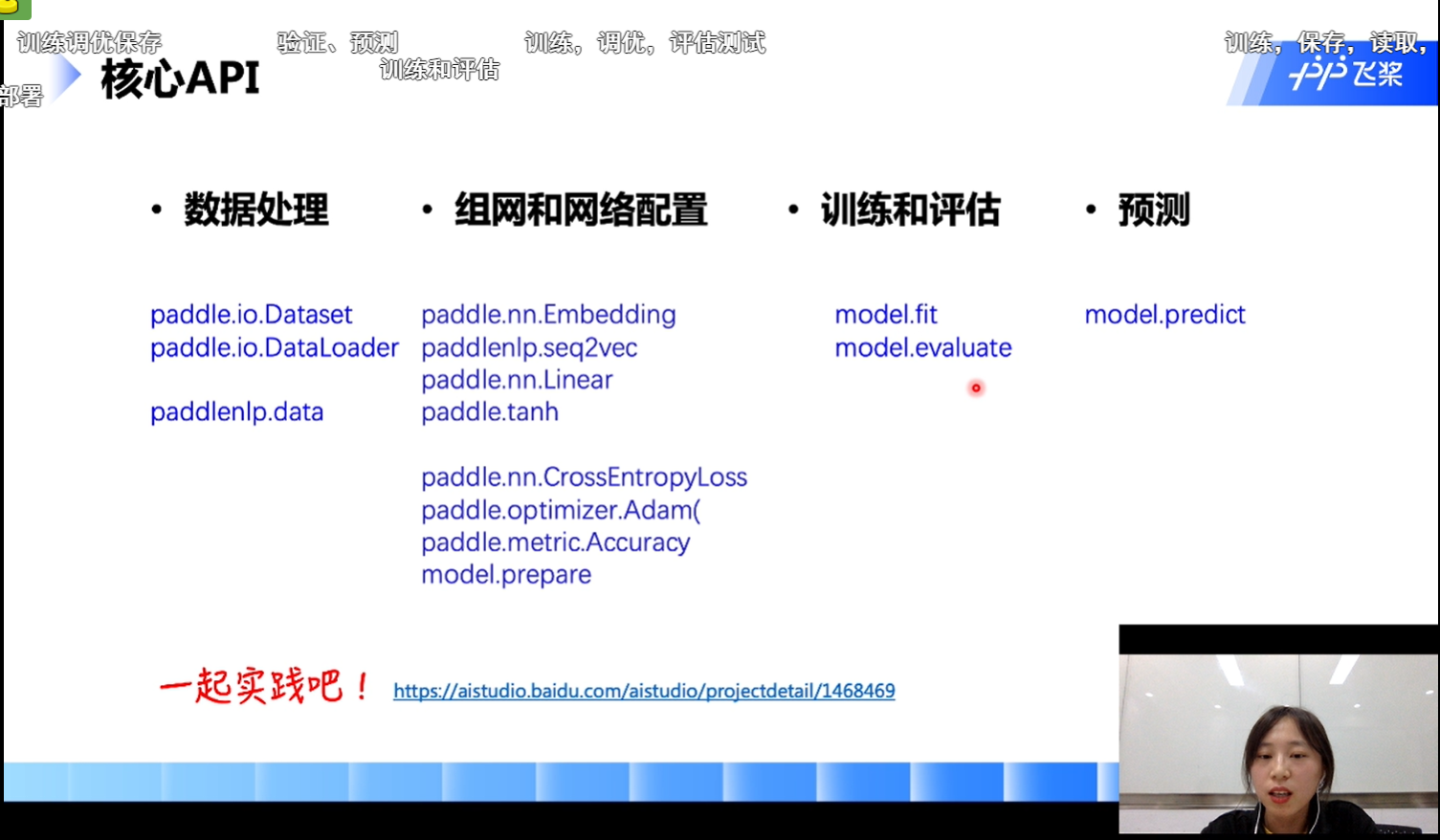
API
- 核心API
get_datasets()
通过get_datasets()函数,将list数据转换为dataset。
get_datasets()可接收[list]参数,或[str]参数,根据自定义数据集的写法自由选择。
train_ds, dev_ds, test_ds = ppnlp.datasets.ChnSentiCorp.get_datasets([‘train’, ‘dev’, ‘test’])
使用飞桨完成深度学习任务的通用流程
数据集和数据处理
paddle.io.Dataset
paddle.io.DataLoader
paddlenlp.data组网和网络配置
paddle.nn.Embedding
paddlenlp.seq2vec paddle.nn.Linear
paddle.tanhpaddle.nn.CrossEntropyLoss
paddle.metric.Accuracy
paddle.optimizermodel.prepare
网络训练和评估
model.fit
model.evaluate预测 model.predict
